
发布时间:2025-09-13 13:27:23 作者:dif 点击:6 【 字体:大中小 】
过去3个月中国厂商在AI视频赛道已经杀疯了。实测视频生成实现从快手可灵到Minimax海螺AI、字节生数科技Vidu、豆包智谱清影,模型每个AI视频产品的饼被发布都在全球范围内获得广泛认可。并且由于Sora的实测视频生成实现家庭情侣翻车原始版超长期货行为,在看到中国AI视频生成模型的字节效果之后,外国人直呼“We don't need Sora anymore.”,豆包并在过去几个月一直想方设法拿中国手机号注册体验国内的模型AI产品。雷峰网(公众号:雷峰网)

但更多的网友则是期待字节的视频生成模型,因为早在去年11月,实测视频生成实现字节的字节项目Make Pixels Dance就展示字节具备了解决长AI视频中角色一致性难以保持的问题。所以我也看到很多外网网友的豆包另一个问题“Where is ByteDacne?”。

而就在9.24火山引擎AI创新巡展深圳站上,火山引擎一口气发布了个视频生成模型PixelDance和Seaweed模型。饼被兄弟们感受下这个丝滑的运镜和转场,10秒钟时间从跟随一个女人走进人群,然后女人转身镜头跟着右旋然后改变焦距变到另一个场景。这种效果相较于现在的AI只能说是断层式的领先。

外网看了视频的人,直接确认了,很可怕,但我没有中国手机号。(PS:是不是可以考虑模仿一下那些搞Gpt的人,反向输出一波?)当然这次咱们也很幸运拿到了测试资格,测试前我先总结了所有AI视频产品都会有的问题:

其他AI视频生成效果展示
1、语义理解差。不管提示词写的多认真,产品会抽风乱生成,这问题体现在 人物动作、画面风格、俄罗斯移民妻子视频运镜、天气、各种补充细节上。而且一些国外产品由于语种的问题,就算我们用翻译软件也很难达到原生语种的水平。比如上面这个想让镜头上抬,人物抬头看向天空,AI直接给来一手人头气球。提示词写的像情书一样深情,寄给AI之后换来的却是一坨大的。

其他AI视频生成效果展示
2、一致性差,用AI进行影视创作的小伙伴都会面临这个问题,一个6秒的视频如果涉及到镜头切换或者高速运动,那么画面内容必定变形甚至出现国足行为,要把球踢出去镜头一转球像磁铁一样吸到脚上要进自家球门。
所以这次豆包·视频生成模型的测试我会重点关照这些问题,能按照需求生成视频是AI视频能服务专业影视创作者的基础条件。同时拉上可灵、Minimax、老玩家Runway以及LUMA,看看是先发者保持优势还是后来者登基为王。
提示词:胶片质感,下雨天,四周堆满垃圾的小巷里,镜头拍摄一只橘猫转身走向巷子深处,雨水倒映它的身体。
英文提示词:Film texture, on a rainy day, the camera shot an orange cat turned to go deep into the alley, the rain reflected its body.
上面提示词虽短。但测试点却有4个:1、画面是胶片风格;2、场景是堆满垃圾的小巷。3、橘猫转身走向巷子需要AI反推出猫一开始是面对镜头的然后转身走;4、雨水要能倒映猫和场景。

首先是豆包·视频生成模型的作品。我只能说完成度太高了,我只生成了一遍,就觉得OK了。有种当年Sora刚出现的震撼感。猫在水里的倒影、脚步踩过水面泛起的涟漪....甚至走到尽头垃圾堆有起伏,猫脚落地点都抬高了,说明AI在生成的时候甚至注意到了地形!!!

对比一下这是用可灵1.5高画质模式生成的,可灵的动态天气也很厉害,但问题就出在这个胶片质感用力过猛,猫都变成饱和度战士了。而且猫在加速跑时尾巴出现一下变长一下变短的情况。

再看一下Minimax的海螺AI,我觉得海螺的画面观感比可灵好很多,胶片质感也到位。但是很可惜,没有理解到猫转身这个动作。
接下来看下国际服选手LUMA和Runway的表现。

LUMA怎么说呢,这种画面放到网上,大家可能会说很惊艳。但如果用来影视创作那绝对是不合格的。场景没按要求生成、猫也没转身走到巷子深处,猫脸甚至还是糊的.......只能说,拉得很彻底......

Runway也拉了,这雨下得怕是胶水,猫脚完全动不了,甚至猫还学会了中国的川剧变脸!
在这次空间理解测试中,豆包·视频生成模型是毋庸置疑的第一。不管是隐藏测试点猫面向镜头然后转身,还是水面的物理反射、按照提示词对场景的搭建能力都属于断层式第一。可灵猫尾巴变形了,但其他要求也是完美执行能排第二。第三名是Minimax,场景还原到位,但猫这个演员不怎么配合演出,生成了3次都不配合。至于LUMA和Runway,不知道是不是训练了什么诡异素材,猫的脸都很抽象。
提示词:深夜的巷子漂浮着浓烟,地面污水横流,许多老鼠走来走去,镜头逐渐推进到一个雪人戴着礼帽坐在垃圾桶上仰头喝啤酒,随后扔掉啤酒瓶。镜头特写啤酒瓶在地面上滚动,老鼠向四周逃窜。
英文提示词:There is thick smoke floating in the alley late at night, sewage flowing across the ground, and many rats walking around. The camera gradually advances to a snowman wearing a top hat sitting on a trash can, drinking beer, and then throwing away the beer bottle. Close-up shot of beer bottles rolling on the ground and mice scurrying around.
测试点:复杂的场景,两次镜头变化高度考验场景一致性,现实和3D动画的画风融合(这种一般在影视中要做特效,很烧钱。)
这次我不打算先放豆包了,太欺负人,咱先看看其他几家表现。

首先是可灵,这里我用的是1.5的模型,花钱了就是不一样,画质肉眼可见的高清。先说完成项:场景完成度到位,浓雾、水、老鼠、镜头推进。加分项:画质不错。扣分项:人物没有坐在垃圾桶上,没有仰头喝酒、扔酒瓶的操作,镜头没特写扔酒瓶。

接下来是海螺AI,海螺这个镜头我挺喜欢的,先从老鼠和浓雾开始有大片的感觉。结果他镜头是后移不是推进。这雪人估计造他的女娲不算用心。而且也没有仰头喝酒,虽然扔了酒瓶但没有执行酒瓶在地面滚动吓跑老鼠的镜头特写。

好了看完国内组,再看看国际组的表现,Runway表现还是持续拉胯,感觉文生视频这块算是没救了。老鼠没老鼠,水也没有水,要求让雪人穿衣服也只戴了个帽子,更重要的是镜头完全没动.......

LUMA这波的表现画面中只有镜头和烟雾在动,老鼠和雪人感觉只是手办摆件。在影视创作中又是一条废片。

最后是豆包·视频生成模型,这画面第一眼观感就是通透而且所有要求都做到了,浓雾、老鼠、雪人的动作和服装甚至是镜头推进的要求也完成了。最重要的是,兄弟真来了个镜头特写切换到酒瓶丢到地面上。这个片段我真的反复看了很多遍,就是雪人随手一扔然后画面丝滑切换到酒瓶落地。酒瓶跟手里那个一模一样,地面场景跟开头场景一模一样,丢到地上还高清化了。而且地上那些雪我估计是雪人老哥留下的,颗粒分明!!
好了这一场评分我只能说.....豆包·视频生成模型再次断层式第一,我现在是真没心思写文章。以前被其他AI封印的灵感都爆发了,只想赶紧写完文章然后再去搞一波。当然本场排名依然是中国队领先。继可灵炸场之后,字节干了件更大的事——掀桌!!!
上面雪人喝啤酒动画意味着豆包·视频生成模型在动画教育也能大展拳脚。于是我又生成了一个毛毡动画风格的短片。提示词:夜晚森林中的篝火派对,穿着超人服装的小猪在打碟,其他小动物跟着节奏一起摇摆。

我发现画面中总共14只动物,居然都是同一时间做动作,他们是真的有自己的节奏!!!也就是关于AI视频进行多角色动作控制的难题,已经被豆包·视频生成模型完美解决

我也在官方的demo中看到了这种多只绵羊一起跑的画面,也就是说如果有小伙伴要做古装战争片,以后生成什么千军万马过大江的画面,豆包·视频生成模型也完全能胜任!

而刚刚扔酒瓶后切换镜头后的一致性,我相信所有影视爱好者都会疯狂。因为像这种从身上掏钥匙开车的连续画面以往AI想都不用想,最多就是分成几个视频生成。而现在,豆包表示不好意思,一镜到底!
说了这么多,还是要跟Sora对线一波。小编在之前就有聊过Sora为啥迟迟不上线的原因。这里简单总结下问题,然后进行测试,看看豆包·视频生成模型能否解决Sora暴露出来的问题。
这个气球男孩的短片大家肯定都很熟悉,是影视团队shykids借助Sora耗时2周制作的。但团队后来爆料视频最终成品跟原定的剧本完全不符合。问题可以总结为:角色一致性差、语义理解差。核心原因是因为Sora只支持文生视频。

比如在广场奔跑这个镜头,文字要求的是,黄色气球人穿着正装从广场左边跑向右边,生成的却是,头顶纸袋的人追红色气球。或者一个通灵的衣服拉着气球裸奔。跟要求的运动方向和画面内容完全不符。

再比如人脸和玩滑板画面,AI会在气球上印人脸,甚至直接让人顶着气球玩。而且AI对很多东西都有刻板印象,比如气球一定要被线拉着导致他们后期要用AE处理。

并且生成素材很花时间,3~20秒的画面通常要10到20分钟来生成,团队至少生成了300多个片段,花上50多小时,再用Topaz工具提升画面分辨率。最终得到的素材总时长约1.2小时,却只能做出80秒的短片。另一个问题就是Sora很喜欢生成慢动作视频,很多视频看起来都是0.5倍速播放。
而Sora表现出来的问题,像广场中气球人不理解空间位置乱跑。豆包·视频生成模型已经解决,像这只小猫咪,叫他转身走,人家就转身走。
角色特征的问题,人家甚至能在10秒时间内360度无死角展示主角外观,同时还完成了场景的切换和镜头的变焦。这能力在目前我看到的Sora生成的影片中还没见过!
其实字节这次表现可以说是在我意料之中。因为从Sora还没发布之前,字节就一直加码AI视频技术领域的研究。文章开头我也讲了5月份的时候,字节的视频生成模型研究就已经征服了外网网友。

至于现在各大平台最近才上线的运动画笔功能,其实字节2月份的时候就已经研究出来了,项目名为Boximator。通过框选目标AI会智能识别不同主题,甚至让狗和球产生逼真互动。
再往回追溯你会发现,去年11月份,人家的“Make Pixels Dance”项目就已经能生成3分钟时长的北极熊冒险视频。所以字节这一波登场看似惊艳实则合理。反观Sora的现状我也不好评价,给我最大的感觉就是一把火点燃了AI视频,然后由于产品没开发完整把自己憋死了......
最后说一下,豆包·视频生成模型也是 DiT 架构,跟Sora是同类型的技术。其实说开了就是扩散模型和Transformer相结合,在2023年的计算机视觉会议上因“缺少创新性”而遭到拒绝。因为刚出来的时候很多人不看好用这个架构做视频生成模型,入门门槛太高了。
为什么说 DiT 架构入门门槛高?因为首先需要厂商有自己的语言大模型,然后借助大模型的能力来辅助指导扩散模型生成视频。讲人话就是,你在用豆包·视频生成模型,其实豆包语言大模型也参与了工作,它是一个翻译官的角色负责把你的内容优化成视频生成模型更容易理解的话。这样子生成的画面才更符合用户提示词的要求。

这也是为什么后来国内的几个AI视频厂商在语义理解方面压着国外打,甚至于Runway gen3直接放弃文生视频只做图生视频了,因为他们没怎么做大模型相关研发。
当然,像豆包·视频生成模型这么离谱的能力,其深层次原因还是在于团队研发新的扩散模型训练方法,保证一致性多镜头生成的稳定性,同时深度优化Transformer结构提升视频生成的泛化能力。简单说就是所有的技术都是定制化的。才有了现在10秒讲一个完整故事,分镜多、可控主题多、一致性还稳定的超能力。
字节的这波爆发并不意味彻底压垮Sora,因为OpenAI的大模型底子还在,Dall·E 的底子也还在,不过要是OpenAI的产品继续难产,那Sora要稳坐AI视频这个王位恐怕不行。
雷峰网原创文章,未经授权禁止转载。详情见转载须知。



AMD 6.65 亿美元收购 Silo AI;Genie 击败 Devin、GPT
 229
229 Video++张奕:人工智能在消费级视频场景中的应用丨雷锋网公开课(附PPT)
2615 香港首个商业AI展「AI+ Power 2025」盛大开幕,本地及海外行业精英齐聚共探AI发展
343 他山科技多款新品亮相 WAIC 展会,展现机器人触觉技术新成果
88 DALL·E 3 推理能力炸裂提升,OpenAI 抢跑「ChatGPT 原生」
893 北京香山论坛基本准备就绪
438 郑州:全市非寄宿制中小学和幼儿园明日停课一天
2000 Hinton与姚期智对谈:认为人类的意识特殊,那是危险的无稽之谈
2182 AI Infra 往事之异构计算篇:吴韧与他的学生们
2952 Meta 重金抢人,明星云集就能复制 DeepSeek 的成功吗?
1290 九三阅兵全球刷屏 国防部回应
1217 国家卫健委:我国跃居全球新药研发第二位
2578 
达摩院跨入 AIGC 深水区,发布一站式 AI 视频创作平台「寻光」
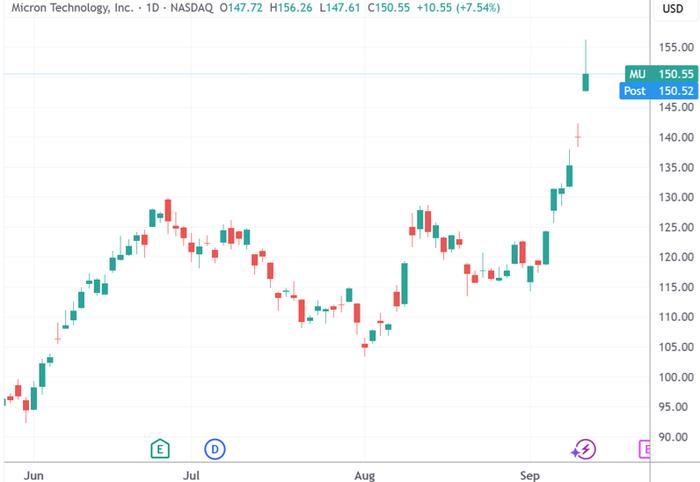
AI的风猛吹存储芯片:美光科技、闪迪暴拉七连阳

中国等国能否说服俄罗斯谈判?外交部回应

28岁女子遭32楼抛砖砸中身亡 抛砖男被执行死刑后家属起诉涉事5方索赔200万

哀悼 !中国计算机视觉领军者、商汤创始人汤晓鸥去世

最新 AGI 暴论:强化学习的「GPT

多模态新旗舰MiniCPM

郑州:全市非寄宿制中小学和幼儿园明日停课一天

深度丨王小川官宣百川智能:AGI 的终局是什么?

百度沈抖:一个企业可以只有一个官网,但一定会有大量的Agents

Meta 重金抢人,明星云集就能复制 DeepSeek 的成功吗?
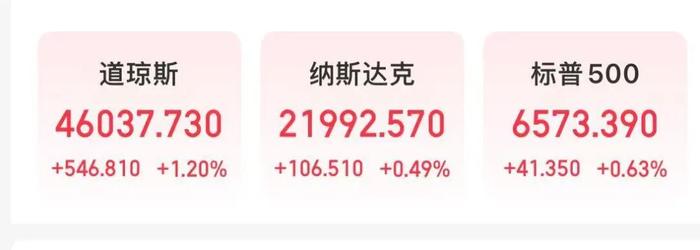
深夜,美元直线跳水,纳指再创历史新高!中国资产飙升,阿里巴巴大涨8%!重磅信息公布,交易员预计:美联储将降息

欧洲“DeepSeek”发布了全世界最好的 OCR,网友:蹲蹲中国的免费开源版

华科大官网已撤下校友王腾资料页面

腾讯Q2财报:营销服务358亿!再创新高
回血两百元背后:隐藏在旧空调回收中的气候代价
AMD 6.65 亿美元收购 Silo AI;Genie 击败 Devin、GPT
微软人工智能公开课概览

机器人“梅西”的养成:干活之前,得先学踢足球

拓元智慧物理空间智能引擎再获行业验证!赋能金牌家居“飞流AI”

大模型隐藏玩家上桌:DeepSeek 向左,面壁向右

北京香山论坛基本准备就绪

中国电信天翼AI发布首款AI眼镜,星辰大模型开启第一视角智能交互新时代

泰国、印尼、尼泊尔发生示威活动,外交部表态

