
发布时间:2025-09-13 13:24:42 作者:i 点击:9647 【 字体:大中小 】
【雷峰网(公众号:雷峰网)消息】上周五,通义全球最大的千问开源大模型社区Hugging Face公布了最新的开源大模型排行榜,阿里云通义千问Qwen-72B表现抢眼,登顶以73.6的首国综合得分在所有预训练模型中排名第一,超越Llama2登顶榜首。产开
Hugging Face的模型天津师范大学实拍体验开源大模型排行榜(Open LLM Leaderboard)是目前大模型领域最具权威性的榜单,收录了全球上百个开源大模型,赶超测试维度涵盖阅读理解、通义逻辑推理、千问数学计算、登顶事实问答等六大测评。首国

通义千问(Qwen-72B)是基于3Ttokens数据训练而成,同时也在10个权威基准测评中夺得开源模型最优成绩,赶超在部分测评中超越闭源的通义GPT-3.5和GPT-4。
这是一个激动人心的时刻,从Llama2开源可商用,迄今5个月,国产大模型开源终于有一个能追上Llama2,大模型开源领域终于不再是Llama2独领风骚的时代,国产大模型开源也由此进入新时代。
从Hugging Face官网公布的开源大模型排行榜(Open LLM Leaderboard)来看,他们是从ARC、HellaSwag、MMLU、TruthfulQA、武汉中学实拍推荐Winogrande、GSM8K来对当前的开源大模型进行测试评估。
从上述截图我们可以看到通义千问Qwen-72B在多个测评中断层领先其他开源模型,其中MMLU、TruthfulQA、GSM8K三个维度的得分远超Llama-2-70B,分别得分为77.37、60.19、70.43,而Llama-2-70B的得分分别是69.83、44.94、54.06。
Qwen-72B得分最高的三大测评:MMLU考察模型的世界知识和语言能力,综合评测LLM的英文综合能力和知识能力;GSM8K考察的是模型的数学推理和计算关系大模型的数学推理能力;TruthfulQA考察模型的常识问答关系模型的常识能力、抗幻觉能力、问答能力等。
而在其他测评ARC、HellaSwag、Winogrande中,通义千问Qwen-72B与Llama-2-70B的差距仅有1、2分之差。
ARC考察模型阅读理解,这个能力关系大模型的语言理解、文档问答、工具调用能力;WinoGrande考察模型的语言推理、指代理解关系大模型的语言理解、语言推理、指代消歧等能力;Hellaswag考察模型的常识和语言推理关系模型的常识和语言推理能力。
最终Qwen-72B以73.6的综合得分在所有预训练模型中排名第一,在这之前,该榜单长期被Meta的Llama2占领。同时,除了阿里云开的通义千问、Meta的Llama2,榜单上还出现了幻方量化的deepseek-67B、零一万物的Yi-34B、百川的baichuan2-13B等中国开源大模型。
国产开源大模型势头正猛。
在评分之外,我们用一道高考数学题来粗略测试下Qwen-72B的表现,发现Qwen-72B解题思路清晰,计算结果准确:

同时,还问了它一道外国人看了头大、极具中国语言特色的复杂语义理解题,没想到Qwen-72B居然深刻理解了中国式的职场“拉扯”:

在复杂逻辑推理上,表现同样不错:

不仅如此,通义千问一经发布,在国外引起了广泛讨论,不少国内外开发者进行了测试和应用,实际使用体验在某些领域还超过了GPT-4:

为什么Qwen-72B能有这么出色的性能表现?
众所周知,一个优质的模型首先离不开团队强大的研发能力,通义千问团队在国内互联网公司中最早探索大模型,据称是阿里全力投入打造的团队;其次,通义千问背靠阿里云,在AI算力基础设施上拥有充足补给;还很重要的是,通义千问一直在奋力发展自己的开源生态,来自应用场景和开源社区的反馈能帮助研发团队不断优化基础模型。
具体到Qwen-72B模型的训练,通义千问利用多达43T的高质量数据进行训练,折合7Ttokens(目前训练完成3Ttokens,还在持续进行),涵盖近20种语言,覆盖网页、新闻、书籍、数学、代码及各个垂类领域,如金融、法律、医疗等等。
综合利用了dp、tp、pp、sp等方法进行大规模分布式并行训练,引入flashattentionv2等高效算子提升训练速度。借助阿里云人工智能平台PAI的拓扑感知调度机制,有效降低了大规模训练时通信成本,将训练速度提高30%。
在训练稳定性方面,模型训练过程中,通义千问团队通过PAI平台AiMaster管理组件监控作业的日志/报错/metric等信息,区分用户错误和系统错误,根据作业类型和容错场景提供管理能力和全链路自动化运维能力,自动剔除故障机器重启任务,使训练过程中人工干预重启频率由日降低到周。
从今年7月Meta宣布Llama2开源可商用以来,Llama2便一直站在全球大模型开源的神坛上,它更是国产大模型早期蓬勃发展的救星,元象唯思的创始人姚星曾对AI科技评论吐露真言,国内大部分大模型都是基于Llama开源来做的训练,他认为没有 Llama 开源,中国的大模型探索可能还要走很长一段路。
但这背后也要国内开发者承担许多“屈辱”,一位大模型公司的CEO曾无奈地告诉AI科技评论,Llama2的中文能力很差。
由于此,一些基于Llama2做垂直行业模型的厂商曾告诉我们,他们要用Llama2必须得先跟国内做Llama2中文化的公司合作,不能直接用Llama2去做训练。
而且Llama2对中国很不友好,在Llama2的开源协议里强调了English tended,其他地区illegal,意思就是中国拿它来做中文的大模型和应用是不合法的,但国内又必须得用。
因为在通义千问Qwen-72B发布之前,我们并没有能跟Llama2比肩的开源大模型,很长一段时间Llama2无与争锋。
由于各大模型厂商选择了“小参数用来开源,大参数拿来商业化”的策略,导致国内大模型开源一直停留在14B,所以国产开源大模型看似越来越卷,实则中国大模型市场还没有出现足以对标Llama-2-70B的优质开源模型。
但很多开发者曾对AI科技评论表示,虽然大模型开源非常丰富,但他们能真正用起来的不多。在一些领域,例如金融行业、医疗行业,以及一些科研机构,14B其实是远远不够的。
直到11月、12月,开源大模型Yi-34B、元象XVERSE-65B、Qwen-72B陆续抛出,国产开源似乎有了新进展,真正跨入了“追赶Llama2”的时代。
而Qwen-72B登顶Hugging Face榜首,超过Llama2这一事件,意味着国产大模型开源开始参与全球竞争,同时,Qwen-72B的出现填补了中国大模型开源长期被Llama2所占据的空白领域。
个人开发者、中国能源建设集团浙江省电力设计院有限公司系统室专工陶佳,他在想要做大模型应用时遇到的困境应该是国内大多数开发者都会遇到的:国外的模型,如闭源的如OpenAI能力是很强,但是API调用不便,而且我们这种B端用户更喜欢自己上手定制,API能做的事还是太少;开源的比如Llama2,但是中文能力一般。
他试了几款,试下来通义千问是最好的。“准确,而且‘手感’很好,没有那些稀奇古怪的 bug”,他说。
有鹿机器人公司正在研发第二代具身智能技术LPLM大模型,LPLM是融合了LLM大语言模型和物理世界大模型。在创始人、CEO陈俊波看来,LLM本身是一个偏慢速的、逻辑推理的、有比较完整的结构性思考的智能系统,而物理世界大模型是一个更偏实时响应、偏直觉的一套思维过程,比方说人类怎么去感知这个世界,怎么去对这个世界做预判,以及怎么去规划我们整个动作思维。LPLM融合了这两个系统,使它们能够很好地配合跟协作,能够从人类的高层的指令理解、到拆解、再到底层对物理世界进行理解和规划。
他们把市面上能找到的大模型都做过实验,最后选择了通义千问,创始人、CEO陈俊波认为原因主要有以下几点:
第一,它是目前至少在中文领域能找到的智能性表现最好的开源大模型之一。
第二,它提供了非常方便的工具链,可以在他们自己的数据上快速地去做finetune和各种各样的实验。
第三,它提供了一个特式量化的模型,量化前跟量化后基本上没有掉点,这对我们来说非常有吸引力,因为我们需要把它部署在一个嵌入式的设备上。
不仅如此,国外一些网友也对Qwen-72B等国产大模型表达了惊叹:


通义千问还开源了18亿参数模型Qwen-1.8B和音频大模型Qwen-Audio,至此,通义千问共开源了18亿、70亿、140亿、720亿参数的4款大语言模型,以及视觉理解、音频理解两款多模态,是业界首个“全尺寸、全模态”开源大模型。
阿里云CTO周靖人表示,开源生态对促进中国大模型的技术进步与应用落地至关重要,通义千问将持续投入开源,希望成为“AI时代最开放的大模型”,与伙伴们共同促进大模型生态建设。
开源、开放成为阿里在大模型领域频频提到的关键词,开源Qwen-72B就是其最好的态度展示。
Meta全球事务主管Nick Clegg曾这样评价开源:开源是消除AI相关恐惧的最佳解药,开源有助于Meta追赶竞争对手。
正如业内人普遍认同的,未来90%的企业会倾向于基于开源大模型发展,依托于开源生态。
如今,有了Qwen-72B的开源,国内大模型也能接上Llama2的步伐,允许各种规模的公司在Qwen-72B上改进这项技术,并在其上构建应用程序。
7月,Llama2开源蓬勃了全球大模型发展,12月,通义千问Qwen-72B开源,使得国产开发者不再“求外”。
雷峰网原创文章,未经授权禁止转载。详情见转载须知。



元象发布中国最大MoE开源大模型 落地应用登顶港台榜
 832
832 拳打可灵,脚踢 Veo 3,谁是物理世界的「懂王」?
2385 最新 AGI 暴论:强化学习的「GPT
1119 10个地区接到一项关键任务
249 第十六届信息安全高级论坛暨2024 RSAC热点研讨会圆满落幕
740 郑州:全市非寄宿制中小学和幼儿园明日停课一天
1205 安理会15国强烈谴责多哈袭击事件 呼吁各方抓住和平机遇
537 前百川联创焦可新创业公司曝光,新项目已上线 App Store
1416 超百万 B 端月活用户,ZMO.AI 用 AIGC 打开营销的潘多拉魔盒
309 董军同美国国防部长影片通话
871 台湾评论员怒批石平禽兽不如
384 实测美团 LongCat:快到极致,但是别说追平 DeepSeek
2049 
老友眼中的于朦胧:读书时就有“男神范”,走红后也重情重义

北大卢宗青:现阶段世界模型和 VLA 都不触及本质|具身先锋十人谈

外资银行“抢滩”消费贷市场 释放何种信号?

以总理批准“E1区”建设计划 直言“将不会有巴勒斯坦国”
奥特曼热捧华人AI制药公司获3.72亿美元融资;李开复称若AI取代工作,可以代言生发广告;AGI或使全球GDP翻倍丨AI情报局

Hinton与姚期智对谈:认为人类的意识特殊,那是危险的无稽之谈

高性能计算群星闪耀时
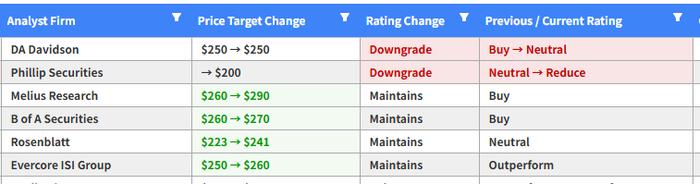
遭两家投行下调评级,苹果陷五年来华尔街最大冷遇
Anthropic 联设 1 亿美元 AI 初创基金;OpenAI推出“小”模型GPT

沈莹任中央统战部分管日常工作的副部长(正部长级)
北大卢宗青:现阶段世界模型和 VLA 都不触及本质|具身先锋十人谈

微软人工智能公开课概览

通用3D机器视觉平台是不是伪命题?
突发!恒大物业:12日9点复牌!公司上半年净赚超4亿元,市值不足100亿元,实控人仍是许家印

独家丨前阿里通义视觉负责人薄列峰,已加入腾讯混元团队
乌称在黑海水域袭击俄一舰艇 俄方暂无回应

为人工智能赋予机器人躯体的“登月计划”项目,倒在具身智能热潮之前

加码AI生态 世纪华通加速建设“ALL IN AI”新框架

他山科技多款新品亮相 WAIC 展会,展现机器人触觉技术新成果

多模态新旗舰MiniCPM

做大模型时代的「Linux」, ChatGPT 仅是开端

机器人“梅西”的养成:干活之前,得先学踢足球

WAIC最强亮点:非Transformer离线AI大模型已大规模量产,大模型商业比我们想得更快

爆料演员于朦胧坠楼者“推理君江小宴”已被禁言

